

Abstract: Hands-on, closed box: Discover what's inside for you, and how we coped.
Train and test an AI – and see how we learned!
The purpose of this interactive conference workshop is to provide participants with hands-on experience training and testing an AI model. This workshop is designed for individuals with little to no prior knowledge of AI and machine learning, but who are interested in learning about the basics of how these technologies work.
During the workshop, participants will be guided through the process of training a simple AI model using a popular machine learning framework. They will learn how to input data and adjust model hyperparameters in order to improve the model's performance. After the model has been trained, participants will have the opportunity to test it on a variety of sample data and evaluate its accuracy. They will also be introduced to common metrics for evaluating the performance of machine learning models, such as precision, recall, and F1 score.
Throughout the workshop, there will be ample opportunity for participants to ask questions and engage with the facilitators and other participants. By the end of the workshop, participants will have a better understanding of the basics of AI and machine learning, and will have gained practical experience working with a trained AI model.
This abstract was written by ChatGPT, prompted and selected by James and Bart
Outline
We're running from 10:45 to 12:30, with a chance of a break 11:30 - 11:45.
We'll get hands-on within the first 10 minutes, and aim that the group shares useful perspectives in the last ¿25? minutes of the workshop. You'll spend 40-60 minutes working through your choice of exercises, working towards something shareable. We'll provide data and example models for exercises where you will need those.
First half – 10:45 to 11:30: We'll show you how to train TeachableMachine, and how we might test the trained model. You'll pick an exercise, gather in groups, and work together on to train and test TeachableMachine yourselves. You'll work towards something that can be shared with the group.
Break – 11:30 to 11:45: You're welcome to keep working over the break, to take a moment and return as the sessions start – or to leave. You're also welcome to drop in for the second half; we'll help you set up, and you should find plenty of information on this page.
Second half – 11:45 to 12:30: We'll take a moment to hear from anyone with something to share, then work towards stuff to share at the end. We'll expect you to be ready to share about ¿25? minutes before the end of the session.
End: You'll have tried training an AI, you'll have tried testing that AI, you'll have worked with others in the group. Maybe you'll carry on training, testing, or working with new colleagues!
What we'll use
We'll work in Teachable Machine – it's easy to train / re-train, shows simple training info, and the trained models can be explored swiftly.
You'll need to use a laptop for this: it seems not to work well from handheld devices. Aaargh.
Our TeachableMachine models ( .tm files), are ready for you to train, and are inked below. Click on the link...
- It might show your an
open in TeachableMachinebutton (it does for James), press that button to open directly. - It might not (it doesn't for Bart) – download the linked
.tmfile, open TeachableMachine in your browser, open the hamburger menu, and chooseOpen Project from File.
There's more in Using Teachable Machine below.
Collaborating
If you need a shared resource, we have a Miro board for this workshop. You can edit it now, and we'll lock it after the workshop so that you can refer to it.
Using Teachable Machine
Teachable Machine runs in your browser, taking friction-free input from your camera and microphone. It runs best on Chrome or Firefox on a laptop. It's built on TensorFlowJs, and can export models that you train. You train it on files, or on input from your camera and microphone. It's built to be trained to classify images, poses, or sounds – you'll pick the project when you start to make a model. You can open an existing project (cloud or local) and save to cloud.
In use, you add classes, then add samples to each class, then train, then see how the trained model responds to input. Using a webcam makes this process swift and intuitive, giving fast feedback to what is oftern a slow but iterative process. It's good to play!
Sample size caveat
To paraphrase TM, Teachable Machine splits your samples into two sets, and labels them training and test. Most of the samples are used to train the model how to correctly classify new samples into the classes you’ve made. The rest are never used to train the model, so after the model has been trained on the training samples, they are used to check how well the model is performing on new, never-before-seen data.
We reckon that the split may be different from training to training, and don't know if it's different epoch to epoch.
This has two implications: 1) use three pictures, and it'll train on two and test its model with the remaining one. Weirdness abounds on this edge. 2) your model may be very different on different training runs, especially if your small sample set has diverse samples.
Training Parameters
Open 'Training: advanced' to see these
Epochs: One epoch means that each and every sample in the training dataset has been fed through the training model at least once. If your epochs are set to 50, for example, it means that the model you are training will work through the entire training dataset 50 times. Generally the larger the number, the better your model will learn to predict the data. You probably want to tweak (usually increase) this number until you get good predictive results with your model.
Batch Size: A batch is a set of samples used in one iteration of training. For example, let's say that you have 80 images and you choose a batch size of 16. This means the data will be split into 80 / 16 = 5 batches. Once all 5 batches have been fed through the model, exactly one epoch will be complete. You probably won't need to tweak this number to get good training results.
Learning Rate: Be careful tweaking this number! Even small differences can have huge effects on how well your model learns.
(text from Teachable Machine)
Training Metrics
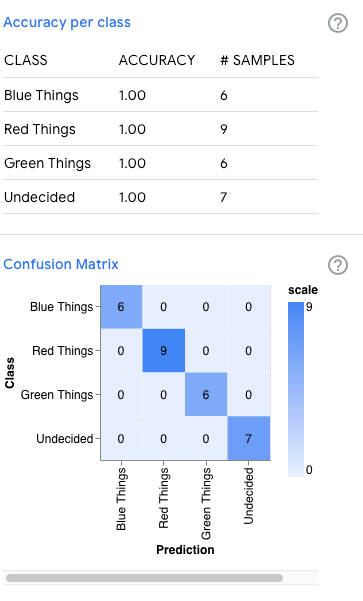
Accuracy per class Accuracy per class is calculated using the test samples. Check out the vocab section to learn more about test samples.
Confusion Matrix A confusion matrix summarizes how accurate your model's predictions are. You can use this matrix to figure out which classes the model gets confused about. The y axis (Class) represents the class of your samples. The x axis (Prediction) represents the class that the model, after learning, guesses those samples belong to. So, if a sample’s Class is "Muffin" but its Prediction is "Cupcake", that means that after learning from your data, the model misclassified that Muffin sample as a Cupcake. This usually means that those two classes share characteristics that the model picks up on, and that particular "Muffin" sample was more similar to the "Cupcake" samples.
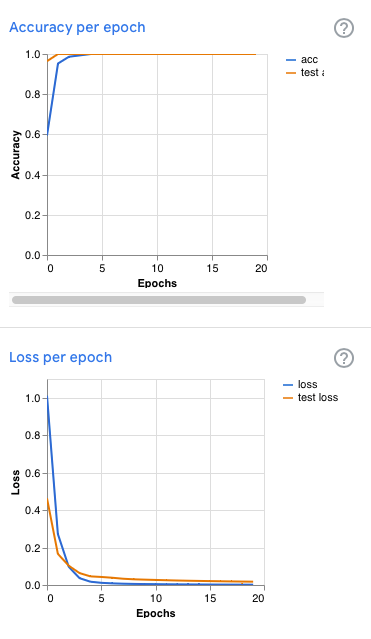
Accuracy per Epoch: Accuracy is the percentage of classifications that a model gets right during training. If your model classifies 70 samples right out of 100, the accuracy is 70 / 100 = 0.7. If the model's prediction is perfect, the accuracy is one; otherwise, the accuracy is lower than one.
Loss per Epoch: Loss is a measure for evaluating how well a model has learned to predict the right classifications for a given set of samples. If the model's predictions are perfect, the loss is zero; otherwise, the loss is greater than zero. To get an intuitive sense of what this measures, imagine you have two models: A and B. Model A predicts the right classification for a sample but is only 60% confident of that prediction. Model B also predicts the right classification for the same sample but is 90% confident of that prediction. Both models have the same accuracy, but model B has a lower loss value.
(text from Teachable Machine)
Vocabulary
Training samples: (85% of the samples) are used to train the model how to correctly classify new samples into the classes you’ve made.
Test samples: (15% of the samples) are never used to train the model, so after the model has been trained on the training samples, they are used to check how well the model is performing on new, never-before-seen data.
Underfit: a model is underfit when it classifies poorly because the model hasn't captured the complexity of the training samples.
Overfit: a model is overfit when it learns to classify the training samples so closely that it fails to make correct classifications on the test samples.
Epochs: One epoch means that every training sample has been fed through the model at least once. If your epochs are set to 50, for example, it means that the model you are training will work through the entire training dataset 50 times.
(text from Teachable Machine)
Training TeachableMachine
TeachableMachine splits your data into two sets – data used to train (85%), and data used to verify that training (the remaining 15%). We don't know how it does that split, nor whether it is the same across trainings.
If you've got more than 16 images, it splits the training data further into batches of 16, 32 or more. You can choose the batch size. We don't know how it splits, or how it treats a small batch.
Starting from scratch, it works through the pictures (or sounds or poses) several times, getting better each time. You can set the number of times by changing the epoch. You can change how much better it gets each time by changing the training rate. We don't know what its starting point looks like, no whether that starting point is the same across trainings..
As it trains and changes the model, it keeps track of the accuracy of the model's predictions. For each epoch (new training), the teaching system judges the accuracy twice: once against the (85%) data it's trained with, and once against the (15%) verification data. It also judges the loss (reflecting the confidence that the model has in its choices).
You can judge the model on its training, which may tell you things more easily than judging how it reacts. You might want to see that the accuracy has increased to a plateau close to 1, that the loss has decreased to a plateau near 0. You may well see that the verification loss drops, and then rises – this can indicate overfitting, where the model has memorised the data rather than generalised its qualities (thanks to Tariq King for the neat phrasing). You might look at the confusion matrix to see whether the data used has posed problems for the model. Training metrics are used to tune a model's training over many different iterations.
The model is trained, thrown away, and retrained until it is good enough to release
We've found Google's course Testing and Debugging in Machine Learning to be excellent, and the TensorFlow playground is a joy. Several playgrounds can be found in the ML Foundational Courses.
Samples, precision, recall, F1 – and how that matches to TM
Models and Data
Red Green Blue Undecided
We trained TeachableMachine to distinguish between red, blue and green things – and to indicate when it can't tell.
We used roughly 160 (AI-generated) images split into 4 classes (zip file) – no need to download because...
Here is the data in TeachableMachine, ready to train. Your trained model may be different from ours.
Here is (one instance) of the trained model to play with instantly, and...
Here are the metrics from that model's training.
Finally, here is a model exported to be Keras-compatible for upload to the AIEnsured tool...
JellyFish
Here is a TeachableMachine model ready to train: https://drive.google.com/file/d/1K5-CsJz9vKzkIIL9BxZo7alYIPa52fT9/view?usp=share_link

Open and closed mouth (1 – Bart and James)
Here is a TeachableMachine, which contains a biased dataset: https://drive.google.com/file/d/1z8cVwCXb6gQE0KbJFqvgu2lHklRLhbW8/
Here it is as a trained model: https://teachablemachine.withgoogle.com/models/B-5e1mKpy/
Here's the data:
- Closed mouth: https://drive.google.com/file/d/18Oeab-7T2a7frchyXAv928kaoRBbOJjI/
- Open mouth: https://drive.google.com/file/d/1lis3Hjhhp1ZZIJHOXlcR3dDoaRU0yVW3/
Open and closed mouth (2 – James)
Tends to overfit. Used in Exercise 9 and 10.
Teachable Machine model: https://drive.google.com/file/d/1IBVgKa0UC2xvqOIm6pmPocdwSh9tIsfH/
Training data used in training this model: https://drive.google.com/drive/folders/1cwi2a-bStqCiTJBMwoflqjzLUlIeLIKD
Exercises
These exercises aren't to be done in order. Pick one that appeals to you. Perhaps you'll find the people around you have a similar interest, perhaps you'll move to find others with a similar interest, perhaps you'll want to work with people taking on different exercises from you, or perhaps you'll prefer to work alone.
1 – Test a pre-Trained AI
... test a pre-trained model as a black box (no training)
We trained Teachable Machine to distinguish between different colours.
Propose some general principles of testing that reflect specific examples of what you've found while testing this model. List principle and example.
Share surprises.
Steps
- Open the trained model.
- Look at the training data to build an expectation of the data that has been used to train.
- Judge the model's ability to recognise colour and shape, using the camera or your own images – how might you expect the model to classify them? How does it classify them? Are these images useful?
- Once you've worked with things you expect it to classify correctly, use your insights to find situations where it classifies something wrongly.
- As a tester, can you generalise some principles of ways to verify that the model classifies correctly? Some principles to help you understand how it might be classifying incorrectly?
- As a tester, think about how the training data might need to change to be 'better'. Better how?
Sources
Teachable Machine model (trained): https://teachablemachine.withgoogle.com/models/dmFmny6zM/
Training data used in training this model: https://drive.google.com/drive/folders/12ihEJYxGF22RL1gP50pDHxUwqnoF-6_4?usp=sharing
Model ready to be trained by you (if you wish): https://drive.google.com/file/d/1JyD9gdn0F_vtyrPVX7Is8kB9tKZY2neD/view?usp=drive_link
Extend exercise / insights
- Train your own version of the model – how different is your version?
- Train again – maybe change the data, maybe change the parameters, maybe train it several times and look at the differences.
- Look at the training metrics in "under the hood" – what do they seem to tell you?
2 – Train One and Test Another (group A)
... train TeachableMachine to do something, and swap your model with another team
Insights and observations from training, and from testing.
Steps
Ask for your secret note from James or Bart.
Train an AI to distinguish between blue objects and green objects. Use the camera, your own data, or data from the Red/Blue/Green/uncertain set.
Once you have built and verified the AI, use "export" to get a web link. Give that link to the team that does Assignment 3, and get a link to theirs (maybe use the shared Miro to exchange – and consider whether you'll share your data and training metrics)
Test the AI trained in Assignment 3. List potential biases and their evidence.
3 – Train One and Test Another (group B)
... train TeachableMachine to do something, and swap your model with another team
Insights and observations from training, and from testing.
Steps
Ask for your secret note from James or Bart.
Train an AI to distinguish between faces with open and closed mouths. Try to introduce a bias in your AI.
Once you have built and verified the AI, use "export" to get a web link. Give that link to the team that does Assignment 2, and get a link to theirs (maybe use the shared Miro to exchange – and consider whether you'll share your data and training metrics)
Test the AI trained in Assignment 2.
4 – Test Outcome of Unbalanced Training
... introduce a bias by using more training examples in one class than another.
Insights and observations from training, and from testing.
Steps
Use this TeachableMachine – set for four classes. Red Green Blue Undecided. Get rid of two of the classes (unknown and green worked for us).
Reduce the first class to a limited subset.
Train (several times) and look at the "under the hood" outputs. Test the resulting model with some of your own images or the camera.
Train an AI with a very limited subset of the second class and full set of the first class. Check the output and compare again
Compare your observations of the two sets of training.
5 – Train an AI with several classes
... how does widening the model's choices affect your training, and its accuracy?
Teachable Machine's own examples typically have two classes. Introducing more brings in more ways that an input can be mis-classified. We'll explore that here.
You'll make your own data for this exercise – use your laptop camera to get several images or poses.
Describe your set of classes.
List ways that your trained model mis-classifies inputs.
Propose general principles of how one might test for these mis-classifications.
Steps
- Decide on your different classes – pick something with more than two options. Try to make few-enough that you can complete the task of training and working with the model in the time available. Consider how the classes differ, and how you'll reflect the difference in your data.
- Make a new Teachable Machine, and train it.
- Train it several times, looking at training metrics and tweaking the training parameters until you feel that you have trained a model you want to test.
- Try it out, looking for mis-classifications.
6 – How Training Size and Variety affects Bias
... train with biased data, and try to get away from the bias.
here's stuff
Steps
Train an AI to distinguish between faces with open and closed mouths. Here's one we prepared earlier.
Try these options (and others which may occur to you)
- train the AI using 1 ‘model’ (team member) with only a few pictures
- train the AI using multiple models with only a few pictures each
- train the AI using multiple models with multiple picture each.
Tip: You'll be tempted to use the camera to test each of your trained models. For consistency, try using a consistent set of test pictures across all of your models. What do you see in the outcome?
Hint: you can also try to diversify the background.
7 – Non-image Classification
... stepping away from pictures into poses and sounds
Teachable Machine is trained to take several classes of input – pictures, poses, sounds. We imagine that many groups will be using images – in this exercise, we look at the differences in training and testing these other classes.
Poses are images, too, of course – but in this model, the AI is trained to treat the image always as a picture of a body.
Describe the model you're building, show the data
List insights from training and testing your model
Propose principles, based on similarities and differences you've seen with other models built in the workshop.
Steps
When starting teachable machine, select a different project, Audio or Pose. These projects use different models from the Image projects, each tuned to work with different media.
You can, again, use real-time input. Audio works on short clips – you might try ot differentiate several words, accents or people. Pose interpret static body poses (to differentiate from hand gestures or expressions).
We look forward to seeing what you train, how you train it, and how you test it!
8 – Metrics and Parameters
... using aggregate metrics from training to gain insight into your model.
While Teachable Machine is exceptionally limited, it computes several typical metrics from training, and provides several parameters to influence training.
How do the metrics help you to judge the trained model?
Describe how you've been able to use one or more of the metrics / parameters.
Propose ways that testers might use one or more of the metrics.
Steps
- Take an existing model from the set above, or make your own.
- Train it.
- Check the parameters and the training metrics.
- Retrain with same parameters – do the metrics stay the same?
- Observe the metrics that change over training. Retrain, and observe differences.
- What do the parameters and metrics purport to tell you about the training?
- What do the parameters and training metrics purport to tell you about the product?
- Does the product's behaviour reflect what the training metrics indicate?
9 – What do Training Metrics tell us about Quality?
... train with the same data several times – look at the differences between trained models in terms of the training graphs, and the observed behaviours.
Propose possible links between differences in training metrics, and model performance, between different models trained on the same data. List supporting examples.
Share surprises.
Training Teachable Machine isn't deterministic – you can get different results even when training with the same data. This experiment digs into that.
Steps
- Open the
Mouth Open - closed: generatedmodel in sources below. - Train it several times – note that you'll throw away the old model when you train with a new – consider training in different tabs / browsers to keep two independent models.
- Characterise differences in the training graphs.
- Observe differences in perceived behaviour.
- Propose links, and if you have time, see if your proposal is justified.
- What might cause this? How can you check?
What might be a non-deterministic input?
- Training / validation sets may be chosen randomly from the input set in TM
- Starting weights of model may be randomised
- GPU internal randomiser
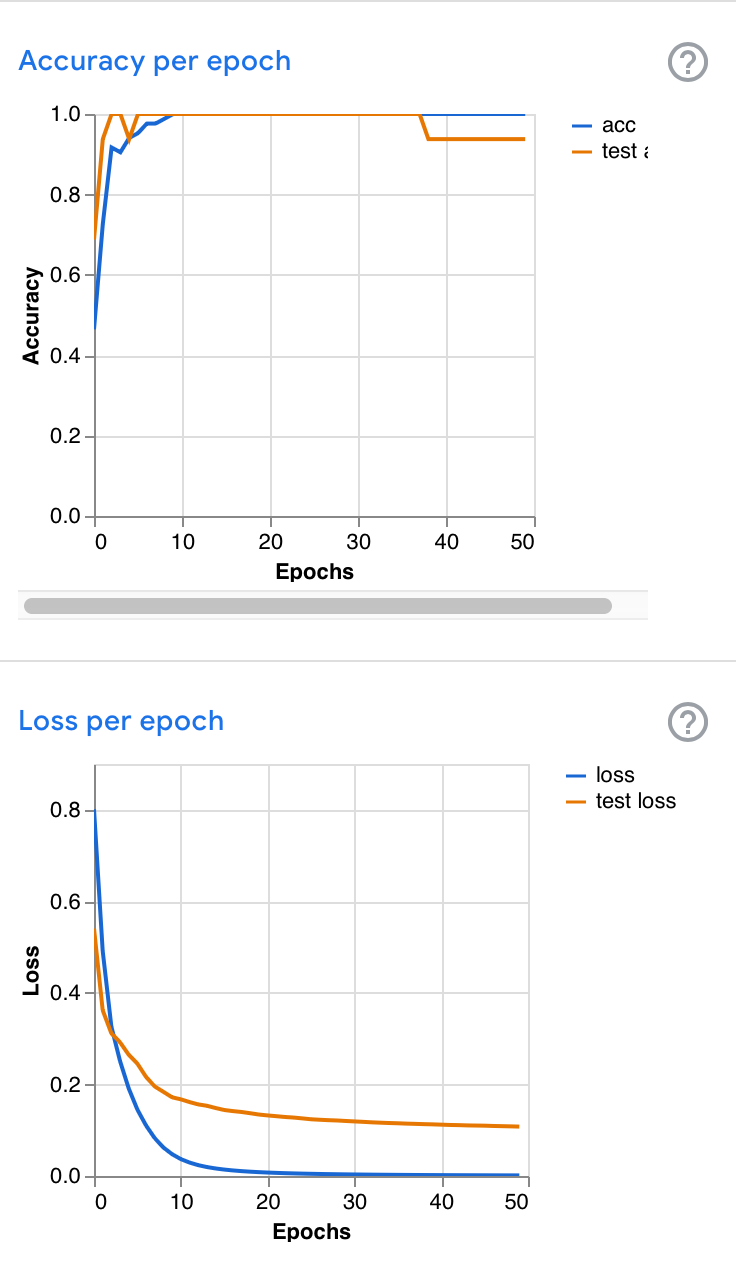
Example graphs
These are from different instances of training on the same data. Note the similarities between the blue curves (training) and the differences between the brown curves (validation). When validation loss rises as training loss falls, the trained model may be overfitting the data; matching the specific data rather than the general problem.e
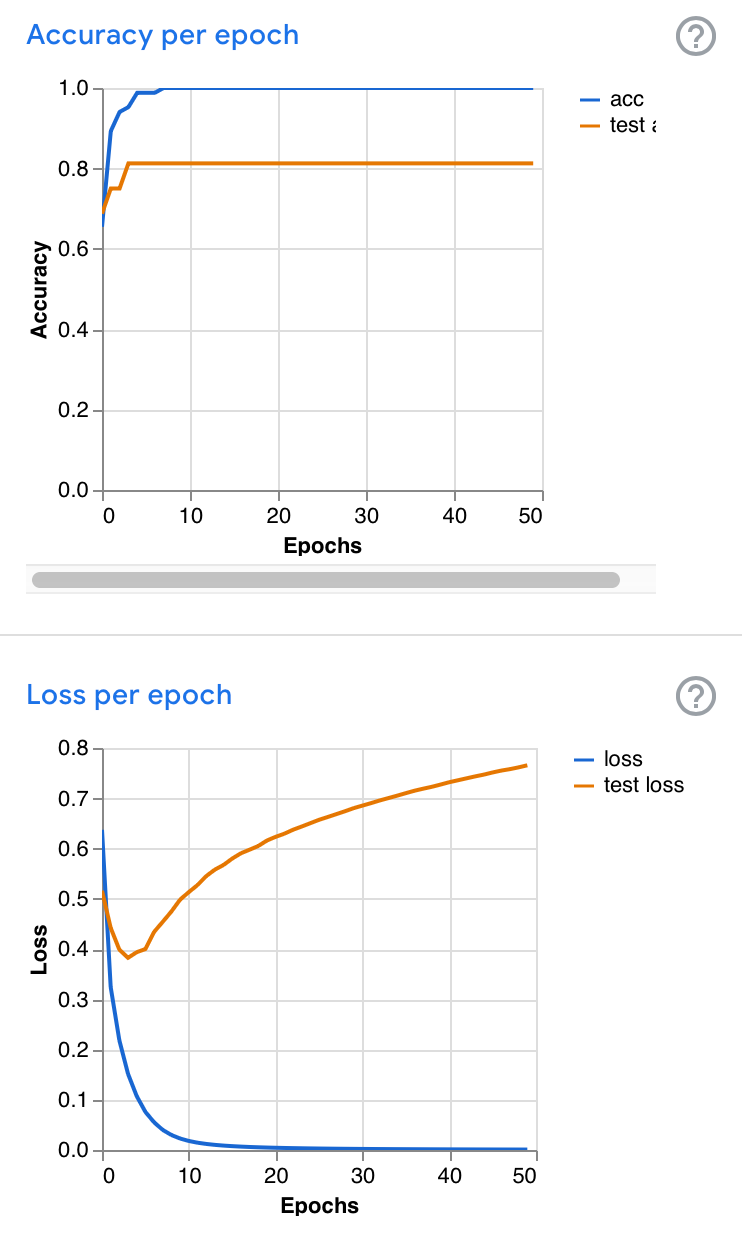
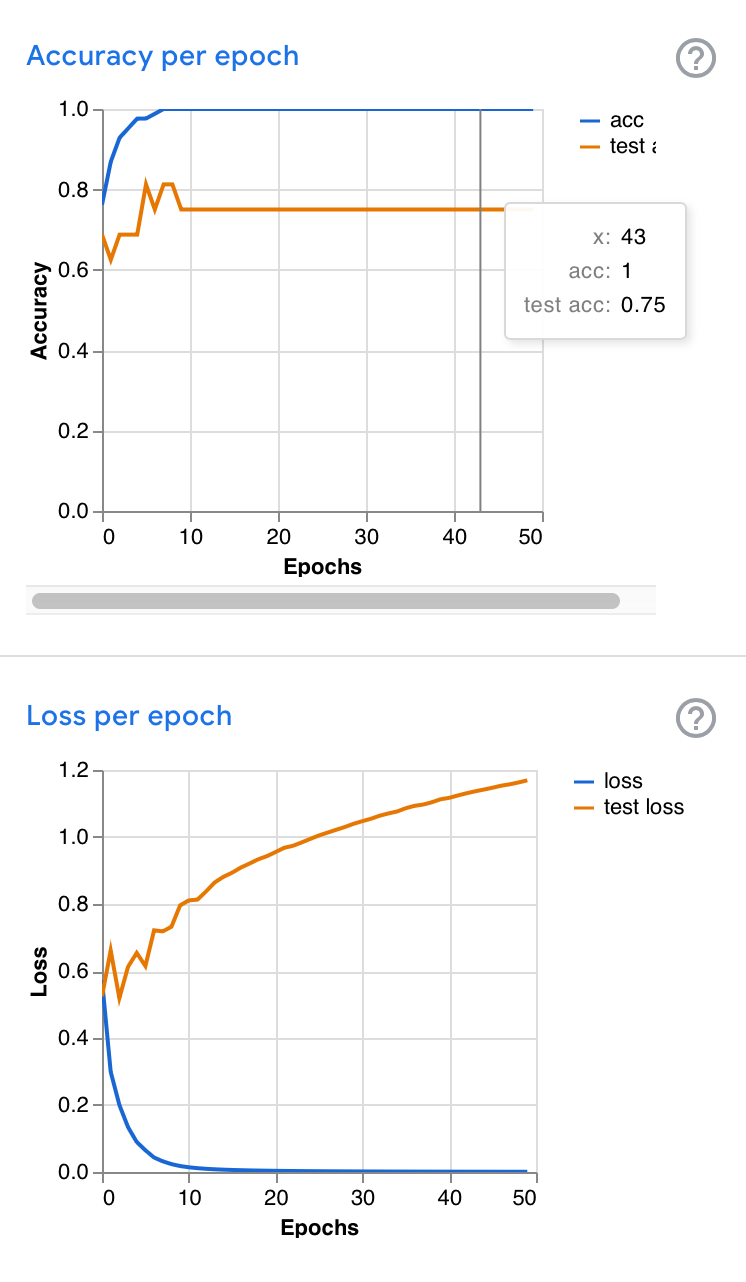
Sources
Teachable Machine model: https://drive.google.com/file/d/1IBVgKa0UC2xvqOIm6pmPocdwSh9tIsfH/
Training data used in training this model: https://drive.google.com/drive/folders/1cwi2a-bStqCiTJBMwoflqjzLUlIeLIKD
Extend exercise / insights
some ideas to kick off with – take your own path...
- Add plenty of pictures of yourself with open / closed mouth (more thn the generated ones.
- Do the graphs become more reliable?
- Does the model?
- How about when you check the model with someone else's face?
10 – changing model quality by changing data and parameters
... adjusting data and training to make a better model
Show two models and identified differences in their behaviour. Link those differences to tweaks of the data and / or parameters.
Steps
- Open the
Mouth Open - closed: generatedmodel below. - Train one instance (probably several times) observing training metrics.
- Decide on some changes – remove data, add data, change training parameters.
- Train another instance (probably several times) observing training metrics.
- Characterise differences in the training metrics and data, and use the two models side by side to investigate differences in behaviour.
Sources
Mouth Open - closed: generated model: https://drive.google.com/file/d/1IBVgKa0UC2xvqOIm6pmPocdwSh9tIsfH/
Training data used in training this model: https://drive.google.com/drive/folders/1cwi2a-bStqCiTJBMwoflqjzLUlIeLIKD
Background: Learning strategies (and tactics...)
For this workshop, we had conversations every couple of weeks, and rapidly realised that we had taken on a subject that we could not possibly understand in a year, let alone cover in 105-minute workshop.
We concentrated on delivering an accessible and hands-on learning experience, auditioning tools and ideas. We de-scoped to labelled classification AI with supervised learning, and developed open space workshops for ethics and generative AI.
As Bart and James worked together, they identified different ways that they approached learning.
- Authority-first – follow the book, ask the expert
- Promise-driven – commit to do something you don't know how to do,
- Confusion-driven – try to understand the part you recognise as a part, yet understand the least
- Foundation-driven – work from what you already know, and expand outwaerds
- Literature survey – what are the key words? Go search, building a collectioon of core vocabulary (words and concepts). Do they mean different thigns to different groups? What are the core articles / sites / authors / groups / magazines / books / exercises / metaphors?
- Ask publicly for help – get comfortable with your own ignorance and curiosity, attract people who want to help, reward their commitment with your progress.
- Aim to teach / write – teaching and writing both require your mind to enage with the subject in a reflective, more-disciplined way
- Value-driven – find and deliver something of value to someone
- Trial-and-error – thrash about, reflect on what happened, repeat with control, thrash more.