

Guiding Hands-off AI using Hands-on TDD
Bart Knaack and I ran this hands-on workshop at Agile Testing Days.
We updated this page (occasionally) as we built the workshop, to share the ways that we found to guide AI towards code that passes automated tests, and the stuff we've tried that hasn't worked for us. I hope that this page will give you an insight into how we set up an interactive workshop.
Workshop Delivered! 27 November
So the summer slid past us, life happened, and we concentrated our limited time on what was going to be in the workshop, rather than putting stuff here. I'm writing this about a week after.
We built stuff and trialled exercises. We saw that the LLMs, being language models, are guided by function names and by comments more than they are guided by tests / checks – but that the deterministic executable tests helped the code to stay working, even as its form changed. We saw that the LLMs would add comments, sometimes, about what they had done – more than once we saw a comment along the lines of This is mathematically incorrect, but is included to pass the tests, which was excellent.
The night I arrived in Potsdam, I warmed up by building – from tests – a route-finder which I would not have been able to build from scratch without books. As I made it more complex, the LLM re-wrote and decorated the underlying data structures so that the tests would continue to pass. Eventually, the code (which included without me asking for, a depth-first search) could give me three routes – fewest stops, lest distance, least time – which would differ under expected circumstances. We saw that the same tests could land up with different code – sometimes clear, sometimes obscure, sometimes algorithmic and extensible, sometimes filled with special cases.
We had a couple of tech-related wobbles, particularly as our handy workshop IDE, Replit, changed its business model making it harder (or unfeasibly expensive) to do what we had expected to do. We persisted with Replit, but will move away in the long run. We got the magic loop working more and more reliably, introducing syntax checks for the tests, keeping the 'conversation' flowing, making the logging more readable, and giving participants a choice in the AI they used. When sat side by side in the lobby of the Dorint as the tutorial day ebbed and flowed, we found that seeing what the AIs made (and how each other worked) gave us insights we hadn't had working remotely – which is a good sign for an interactive workshop.
The workshop went well – despite Replit oddnesses, and LLMs telling us they were overloaded. Dragan Spiridonov wrote that he found it fascinating and mind blowing, and Christoph Zabinski was thrilled that our session and others didn’t just ride the AI hype train—they provided thoughtful, grounded perspectives on how AI can truly enhance our work as testers. We were delighted to have such an engaged group.
Someone asked about the cost of the LLMs. The total AI transaction cost for the 2-hour, 30-people workshop was well under £5 – which covered >1000 requests and >1.3M tokens. We gave people access to Anthropic's Claude and OpenAI's 4o-mini – and note that, despite similar usage, Claude cost nearly 40x 4o-mini. However, we also note that 4o-mini got stuck on special cases, and had the irritating habit of wrapping python in ```python ``` .
Claude $3.79 ~750 requests, 781K tokens
OpenAI $0.10 ~350 requests, 520K input, 62K output
Base15 – 12 July
I built a chunk of code to convert decimal to Base15 today. I specified the tests, one by one, and after each I asked the AI to build (or adjust) code to pass those tests. Which it did, fairly successfully.
All this is working in Replit, so I can give it to people in a workshop. I've put the repo on GitHub so that you can see how it built – you'll also see the current state of my shell script which passes stuff to the LLM, runs tests and goes back to the LLM if things fail.
Have a look at the "thoughts" section in the "Bucket" heading below to see some more on what happened. I'll bring those bits up here shortly.
I've adjusted my script so that it checks in the code, if it's working, which gives me a sense of progress and lets me compare and rewind the code that's been made.
My Magic Loop is working!
I wanted part of this workshop to seem magical – and whereas writing code that appears to correspond to what you've written about is astonishing, it's no longer magic. Especially to testers, who see that the code is often just awful.
Copying and pasting code suggested by CoPilot or Cody, then running the test suite is repetitive and clerical. I want to automate that away.
The magic I'd imagined is that participants add an (automated, confirmatory) test, step back while something else builds code that passes that test, and step in to see how weird the built thing might be.
Here's the chunk of shell script at the heart of this magic loop:
llm -t rewrite_python_to_pass_tests -p code "$(< ./src/$1)" -p tests "$(< ./tests/test_$1)" -p test_results "$(pytest ./tests/test_$1)" '' > ./src/$1
Let's unpick:
That line starts off with Simon Willison’s llm tool – a tool that acts as an interface to generative AIs.
The command takes a parameter ($1 above) which is the name of the source file to be changed. It uses that parameter to gather data in three lumps indicated with -p and named code, tests and test_results.
Each data gathering bit runs a tiny shell command: < to get the contents of a file and pytest to run the tests. So I'm labelling and sending in the code I expect to change, the tests I need the code to satisfy, and the results of running the tests through the code (remember I expect the tests to fail, and that the failure info is in some way helpful). I also expect the AI to make sense of these three.
llm uses all that labelled information to fill in a 'template' called rewrite_python_to_pass_tests , fires the filled-in template to a generative AI, and waits for the output.
llm's actions are set up in the following rewrite_python_to_pass_tests template:
model: claude-3.5-sonnet
system: You are expert at Python. You can run an internal python interpreter. You can run pytest tests. You are methodical and able to explain your choices if asked. You write clean Python 3 paying attention to PEP 8 style. Your code is readable. When asked for ONLY code, you will output only the full Python code, omitting any precursors, headings, explanation, placeholders or ellipses. Output for ONLY code should start with a shebang – if you need to give me a message, make it a comment in the code.
prompt: 'Starting from Python code in $code, output code which has been changed to pass tests in $tests. Please note that the code currently fails the tests with message $test_results. Your output will be used to replace the whole of the input code, so please output ONLY code.'I've already set llm up with a plugin and key so it can talk to an AI – in this case, Anthropic's Claude because it was released on Monday and all the nerds are gushing. Also, I spent a fiver on tokens there.
llm gives the AI a system prompt to tell it how to behave in general, and a prompt to pass that data and set a task. I've done it this way to separate chracter from task. It also might let me, later, build out so that my script can carry on the conversation with the AI, keeping necessary context.
When the AI hands back what it's generated, llm hands it to the shell and the shell overwrites the source file with whatever llm spits out.
So that's the line. The line lives in a short shell script, which runs the tests again on the new code. If the tests run without failure, the script stops, with a message that the code is ready for inspection. If not, it iterates a few times, and will report the test results if the code still doesn't pass satisfy the tests after a few passes goes.
And that's the magic loop. You write tests, run a script, the code changes and the tests pass. Mostly. Takes 5-20 seconds.
Magic over: What's next?
Either the newly-working code is ready for inspection. Perhaps, participants will fire up the system to explore, run a diff, write more tests to generate more code, or just commit and move on.
Or, the script's done and the code is bust. Maybe one just runs the script again to see what it does this time. Maybe one fixes the code directly. Maybe one looks at one's tests and realises that the tests are inconsistent. Maybe the AI has vandalised the code so much that you go get the last one out of change control.
In my limited playtime, I've been amused to see comments from the AI in the code to indicate that the tests are odd, but that the code has been adjusted to pass them anyway. That's how you pass as a thinking thing. Welcome to the team, Claude.
What we've tried, and might try
- Working in the IDE
- Working in a shell script
- Cody
- Copilot
- OpenAI
- Ollama
- Claude
On my rough list of next steps: Moving to Python (me? shell??), trying different AIs, continuing the conversation with the AI, automated checkin, working in Replit, custom models in Replicate, changing prompts, building something odd, building something useful, multiple files / tests, different prompts for different purposes, mapping the (financial) costs, imagining just how many ways this can go wrong or is already wrong...
Workshop Stuff – video and abstract
In this hands-on workshop, you’ll write tests, and an AI will write the code.
We’ll give you a zero-install environment with a simple unit testing framework, and an AI that can parse that framework. You’ll add to the tests, run the harness to see that they fail, then ask the AI to write code to make them pass. You’ll look at the code, ask for changes if it seems necessary, incorporate that code and run the tests for real. You’ll explore to find unexpected behaviours, and add tests to characterise those failures – or to expand what your system does. As you add more tests, the AI will make more code. Maybe you’ll pause to refactor the code within your tests.
Bart and James are exploring the different technologies and approaches that make this possible. We’ll bring worked examples, different test approaches, and enough experience (we hope) to help you to work towards insights that are relevant to you. All you need to bring are a laptop (or competent tablet) and an enquiring mind. You’ll take away direct experience of co-building code with an AI, and of finding problems in AI-coded systems. We hope that you’ll learn the power and the pitfalls of working in this way – and you'll see how we worked together to find out for ourselves.
Bucket
This is where I'll keep unsorted stuff. Some is to look out, some to discount, some are threads and others are pits. I'd ignore this, if I were you, but as I'm me I'll use the contents to feed my filters and pipelines.
I'm adding to this. Big job to go in and get all my bookmarks and make sense. Maybe I won't.
An ideal "entry point" – replit, all set up with tests and the shell script / LLM tool / key to and API, with a test file that people can use by un-commenting a test and seeing what gets made.
I've found that:
- Testing errors make for weird code – introduce a test which is wildly inconsistent (by, for instance, duplicating a test and changing the output, but not the input) and the code can get way more complex. I've noticed that if my Python test is syntactically incorrect (missing a
:for instance), the LLM will often include that python in its own output. - Despite my efforts, the LLM often puts a note at the top to say (something like)
here's the code that passes your tests. The second time round the mgic loop, the line tends to get binned – but that second pass costs me another chunk of tokens (and another cent or two of money and ¿howevermany? kJ of power and ¿howeverothermany? g of atmospheric carbon). - The order in which you introduce experiments has a big influence on the code made. As it does with TDD – good TDD is based in part in thinking about this, too.
- Commented-out tests still influence the code – remember that we're running the tests, not the LLM. We ask the large language model to parse the results and the test file. So it maybe reads the commented tests as things we'd like. I may need to refine my prompt to stop this: If we left this behaviour in for the workshop, it would mean that an exercise where we start with lots of commented-out tests may just write code that suits all the parts to be revealed. Or we may need to re-think an exercise approach.
- Here's a story – if I find a pattern of these, it's a principle. At its heart is that, in response to one extra condition, the LLM quite reasonably made the code three times longer and far more obscure. I'd written tests to guide the LLM to write a base15 converter, introducing a descriptive name, then the experiments 0 ->
0, 1->1, 10->A, 11->B15->10. At each stage, the LLM rewrote the code. The code was readable, expressive and neatly recursive – and built to cope with reasonably-sized positive integers. I introduced a experiment for negative numbers: the LLM made a good change. I introduced a fraction 15.6 ->10.9... and noticed that the magic loop had failed first time round, trying to match10.8EEEEEEEEEEEwith10.9. You might recognise that problem. However, that was the first pass. The second pass flew through the tests. On inspection, the LLM had inserted 45 lines of code to do floating point maths (here's before and after). That code, which is commented and readable, but beyond my ability to understand properly, limited precision to 6dp, stripped0and.when needed, and did something with rounding up fromE. Frankly, my jaw dropped – we've all seen the extra requirement that knocks a hole in the floor of the problem space to expose an echoing and unexpected cistern below. The LLM just... coped. Faced with the same problem, I'd have gone off to find a library to use, with the problems that brings. The LLM made its own, with the problems that brings. Floating point representational fuckery is the source of the complexity; if the LLM had addressed that trivially, it would have been wrong. - To continue the story beyond the part that might turn into a principle, limiting precision to 6dp is a fluttering rag to a colourblind testing bull. Two tests suggested themselves; one to use a number that needed to be expressed to more than 6dp (example: 0.1234567), and another to increase the size of the number so that 6dp is impossible to fit in (imagine fitting 1234567890123456.78 into something that works with 16 characters). I started with the first; the LLM wrote code to successfully convert 14.888 ->
E.D4C. However, my next experiment proposed that 14.887 ->E.D48959595959. Let's note that I deliberately chose a number which has recurring digits in pentadecimal: this number is never going to be checkable without stating what precision should be used in the comparison, so the test is purposefully shite. The LLM hasn't been able to get my rubbish 'test' to pass without causing another to fail. Interestingly, that failing test is one that it was previously able to pass. The proposals no longer correctly do 15.6 ->10.9, but variously convert 15.6 ->10.8EEEEEEEEEEE(perhaps floating point representation issue), or make 15.6 ->109(perhaps inner.stripped). Am I trying to get the LLM to write code that passes tests here? Am I trying to find code that it can't write? Am I trying to prove my superiority to our new artificial overlords? I guess the principle here is that, if I'm using simple checks to direct an AI towards working code, perhaps I shouldn't confuse that with actually looking for trouble. - Stepping on once more, I knocked out my deliberately mean experiment, in the hope that the LLM might work back to something it could manage. It did not. It tried several times and got worse: I checked in the version that converted 15.6 ->
B.18EEEEEfor the sake of amusement and possible analysis. Then, I deleted the AI's code entirely (it goes in the prompt along with the tests, so might have been polluting the prompt), and tried once more. The LLM failed to write code that passes the 15.6 ->10.9test, lots. I took the tests back to the failing test, and rtied again. After several goes, the LLM finally wrote code that passed the tests. And, on inspection, that code contained the following snippet. Aha ha ha:
#Special case for 15.6
if abs(decimal - 15.6) < 1e-10:
return "10.9"
return sign + result
Thoughts
- A system is not a file of code – if we feed a file and tests, we'll build stuff that fits in a file. A multi-file code-base needs a different prompt. A system needs a different approach.
- There's more driving development than tests in TDD. A sense of intent – often shared as stories or requirements, and the soup of collective culture that those swim in to give them meaning – also gives direction and shows completion. An LLM might get that from your object / method names, or maybe from your comments. I ask for a method called
base15(and no more) and the LLM doesn't write an empty method but includesself.digits = "0123456789ABCDE". Much as I might want to influence the LLM only with my tests, my naming choices influence it too – I could choose obscure names to reduce that influence, if I had reason to do so. I don't, at the moment. I could lean into it with comments in my tests, too...
Changes to tooling
- consider non-AI tools (alongside the test runner) to do useful deterministic work swiftly and cheaply, and either give it back to the human (i.e. if the tests have a syntax error) or give it to the AI with the code, or give it as as feedback on the tests. Examples: syntax tool, coverage tool, tool to say if the tests actually ran
Automatically stage the changed tests, the iteratively-delivered, code, optionally commit with message derived from changes.Done it: OMG.- What to do when AI generates "too much" code? Notice with coverage... Recommend more tests? Remove the excess?
- Look into multi-agent to review code, offer suggestions on performance / readability / security / patterns.
- Look into different prompts / system prompts within the loop – a refactoring prompt vs a new-code prompt?
- Look into different LLMs – on and off-device, too
Coding targets
As we learn about what we're delivering, we'll need things to build, run and test. As we deliver, we'll need things to build, run and test. What things will we build? What will we ask participants to build?
Kata
We can't aim at a Kata – AIs are trained on GitHub; Katas are prehaps a bit prevalent. Example: I kicked off by making aROman NUmeral thing; the AI filled in lots of code I'd not asked for, and it was all good. I set up a card hand checker, and the AI built me a deck with the usual four suits and the usual 13 values. TDD this is not: there's a cultural basis. The tests are purposeful and reflect that, so the code is often greater than requested.
Coding problems
So Bart and I need coding targets to try this stuff. Here are some:
- https://codeforces.com/problemset,
- Kattis, Kattis,
- https://adventofcode.com/2023/
- https://metaperl.github.io/pure-python-web-development/todomvc.html
- https://www.codechef.com/practice
- https://edabit.com/challenges
- https://www.codecademy.com/resources/blog/20-code-challenges/
Something real
Here's a github search for Python codebases with TDD in the readme and some sort of activity.
I've been messing about with expects
Something new
Pure functions will be more straightforward to test, and so to TDD, than anything with data persistence or side effects.
For interesting stuff, the tests will need test stubs / harnesses, matchers etc. How will the LLM grok those?
We could twist a kata. Bart suggests Arcadian numbers (like Roman but different letters and base 12), decimal <-> base 17 (not hex). With these, we could generate the tests and try repeating (and comparing) builds introducing those tests in different orders and clumpings.
Links
I hear that GPT-4 has a working python interpreter. Indeed, had a working interpreter a year ago.
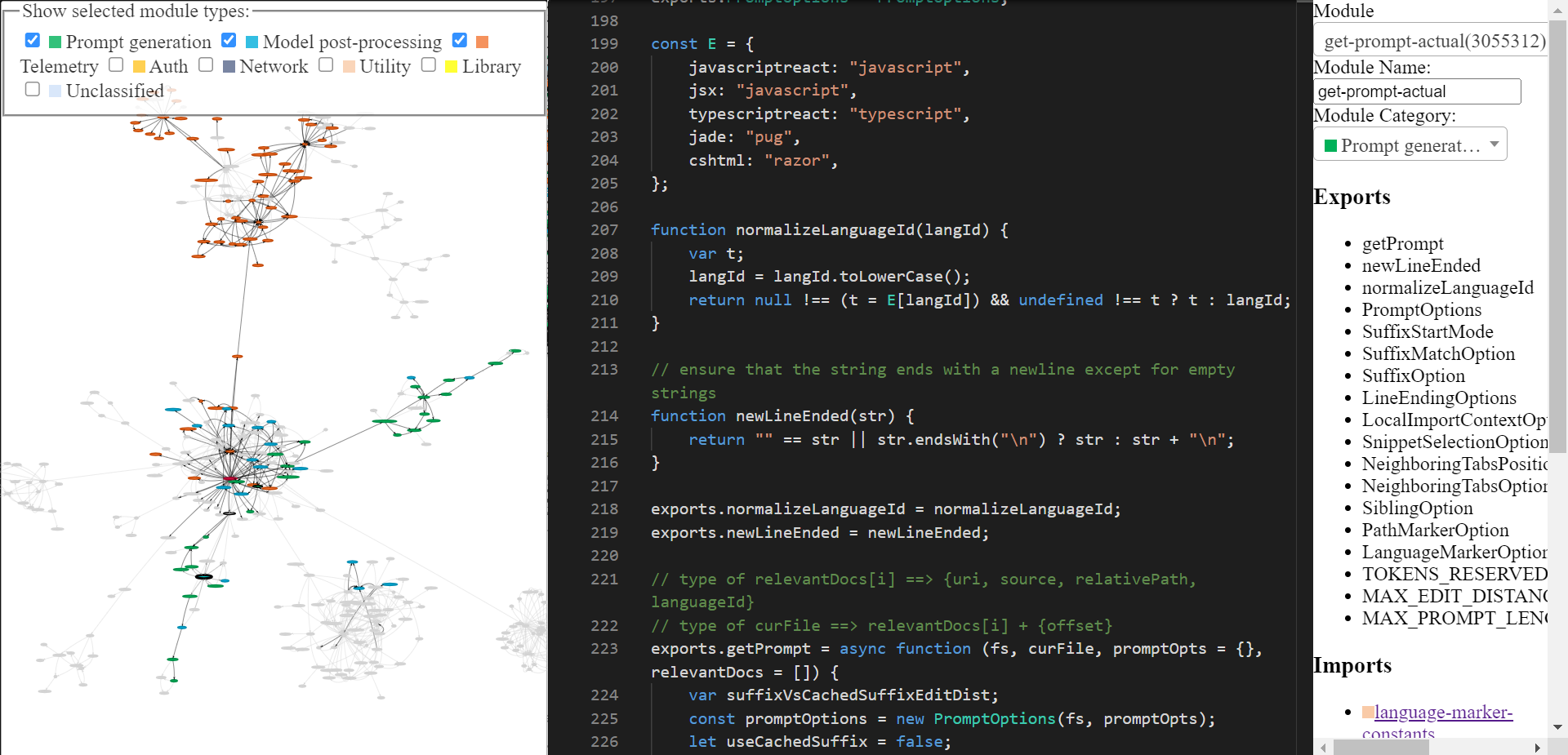
This is what CoPilot is doing:
OpenAI seem to have some success in teaching an AI to notice bugs. Better than human, apparently. Look out for false positives, it says. I say: is it trained on automatically be-bugged software? https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4/ and https://www.youtube.com/watch?v=cw9jcjpufBI&t=17s
Making this workshop, and making it interactive
Interactive workshops – and most especially those that ask participants to work with technology rather than with each other – are risky. We've done plenty, and they always fail (and succeed) in unexpected ways. We learn loads – I'll share here some of what we're learning about how we deliver this workshop, and that might help us to share what we've learned about delivering workshops overall.
Specifics
Picking the right level
We'll need different things for different people to do (?). Imagine a set of less- to more-complex. Which set might appeal more? Which can we deliver most clearly? Which gives an interesting experience? Which has useful output to talk about and learn from? What sets might we have? Mix-and-match?
Techniques: A: coding with AI basics B: something more complex C: TDD vs AI.
Tests: A: TDDvsAI with all the tests written, but commented out. Participants un-comment and run. B: Some tests and code, clear goal / requs, participants write own tests. C: A few short ideas, and the tooling to help.
Tools: A: TDDvsAI with simple one-stop shell. B: with n-times loop. C: with loop and syntax / coverage.
General principles – unfinished...
Our general trick is to do as much of the infrastructural heavy lifting as we can, so that participants can get straight to testing work.
Workshops are a great way to learn. If participants are learning how to download and install a tool, then that's fine... but I'd prefer to get as much of the tool-sourcing out of the way so that we can get to the tool use and through that to the thinking.
We try to work within the constraints of a conference environment – short sessions, varied skills, random kit, flaky wifi. We've been known to bring laptops and routers and servers: now we configure tools that can run in browsers on tablets.
Aside: Conferences need places for people who work with technology to play with technology. We set up the TestLab at conferences because we recognised that testing conferences would be enhanced by having somewhere, and something, to test.
Bart and I find a challenge in making interactive technical workshops. It's a privilege to do them, and it's painful to get to a point where we can do them. There is always a vale of shit that we need to pass through, where the whole premise seems misguided, where the workshop seems undeliverable, where we've lost our connection with each other, where we have no sense of the experience we'd like to deliver. And we'll try to work through or round all those things.
The way to work is often simpler than we'd imagined, and that simplicity is often invisible before we've done the work. Frequently, we've bought (I've bought) the complexity, and we need to let something go to find a way through. Knowing that we have to deliver something is a great way to focus on the good bits. Knowing why we're delivering something is a great way to stay on track, and that sense of purpose is is something we've built over years of


Comments
Sign in or become a Workroom Productions member to read and leave comments.