

Testing Transparently
ATD2025 keynote, Elizabeth Zagroba and James Lyndsay
Scenario: “the tests all pass – but this is generated code. What is weird?”
This has been built for a conference audience of testers, and for Elizabeth and James. But they’re imagining this as a web-based tool to allow teachers to swiftly build crosswords for kids. Commercially, it’s part of a package, rather than a paid-for service.
subject2_e – used at AgileTD
Join us exploring this word grid generator – version subject2_e
Test Resources: test runner, user info, decisions made while building, build diary and agent info.
Examples: keynote words 10x10, 3x3, 5x10
Other versions
final_a
Explore this word grid generator – version final_a
Test Resources: test runner, user info, decisions made while building, build diary and agent info.
Examples: keynote words 10x10, 3x3, 5x10
final_b
Explore this word grid generator – version final_b
Test Resources: test runner, user info, decisions made while building, build diary and agent info.
Examples: keynote words 10x10, 3x3, 5x10
subject2_f
Explore this word grid generator – version subject2_e
Test Resources: test runner, user info, decisions made while building, build diary and agent info.
Examples: keynote words 10x10, 3x3, 5x10
Building
These were built using agentic tool amp.code, with the following prompt:
We've lost the css, index and all the javascript. We do have the documentation, and all the tests. All the tests were passing before. Please read everything in the project (but ignore the change history). Re-create the source from the docs and the tests, ensuring that all the tests pass and that the decisions are respected.
When you're done, document your actions in a file @diary.md
You can build versions yourself, using the files above.
The versions prefixed subject were built with amp running primarily on Claude Sonnet 4.5. The versions prefixed final were built with slight differences to the documentation and tests, and by that time amp was using GeminiPro. While we would have preferred the slightly simpler needs and tighter tests of the final versions, the generated UIs had enough irritations that we felt participants would be distracted by those bugs, rather than play with the deeper code.
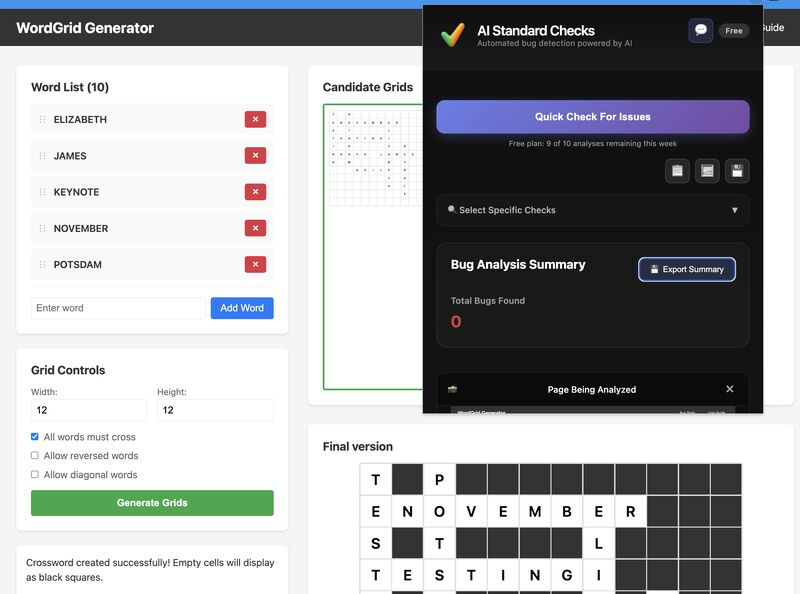
After the keynote, we ran subject2_e through testers.ai's tools, which reported finding 0 bugs.



Comments
Sign in or become a Workroom Productions member to read and leave comments.